分布式锁解决方案
分布式锁的概念
在单体应用中,对于并发处理公共资源时例如卖票,减商品库存这类操作,可以简单的加锁实现同步.但当单体应用服务化后,在分布式场景下,简单的加锁操作就无法实现需求了.这时就需要借助第三方组件来达到多进程多线程之间的同步操作.
分布式锁:在分布式环境下,多个程序/线程都需要对某一份(有限份)数据进行修改时,针对程序进行控制,保证在同一时间节点下,只有一个程序/线程对数据进行操作的技术
分布式锁的执行流程
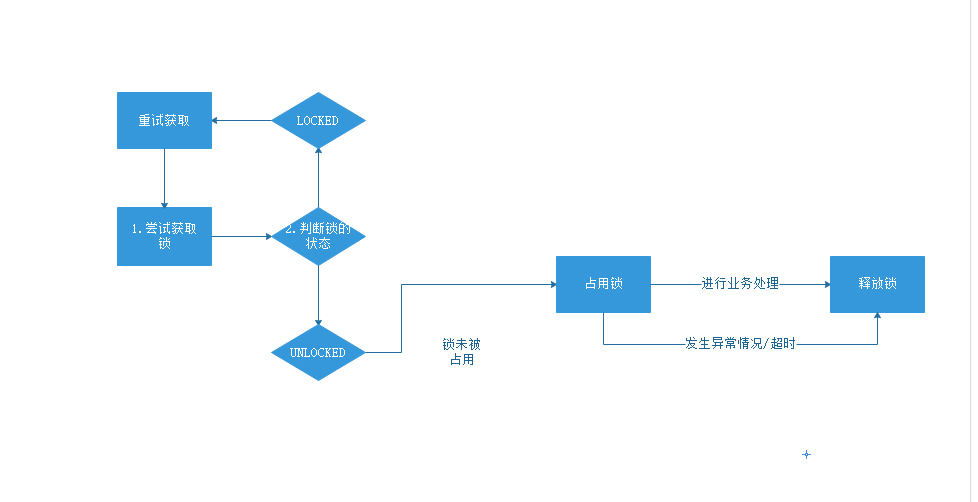
常见的解决方案:
- 基于数据库的唯一索引
- 基于数据库的排他锁
- 基于Redis的
EX NX参数 - 基于ZooKeeper的临时有序节点
基于数据库的唯一索引
步骤:
1.创建一张表,表中要有唯一索引的字段用于记录当前哪个程序在进行操作
2.程序访问时,将程序的编号insert到这张表中(保证这个编号符合规则可以区分)
3.insert操作成功则代表该程序获得了锁,可以执行业务逻辑
4.当其他相同编号的程序进行insert时,由于唯一索引的限制会失败,则代表获取锁失败
5.当占用锁的程序业务逻辑执行完毕后删除该数据,代表释放锁
基于数据库的排他锁
以mysql为例的innodb引擎为例,可以使用for update语句来给数据库表加排他锁,当一个线程执行了for update操作给一条记录加锁后,其他线程无法再在该记录上增加排他锁
步骤:
1.开启事务
2.在查询语句后跟for update 例如 select * from tb_goods where id=1 for update
3.成功获取排他锁的线程即获得了分布式锁,可以执行业务逻辑
4.执行完毕后需要commit提交事务来释放锁
==这种方式需要关闭数据库事务的自动提交==
以上两种通过数据库来实现分布式锁的方案比较==简单方便,可以快速实现==,但是基于数据库的操作,开销非常大,对服务的性能存在影响
基于Redis实现分布式锁
redis实现分布式锁最核心的方法setnx,setnx的含义就是set if not exists,其中有两个参数setnx(key,value).该方法是原子的,如果key不存在,则设置当前key成功,返回1,如果key已存在,则设置当前key失败,返回0;
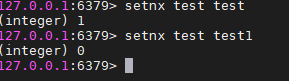
锁超时
理想情况下,当某个程序抢占了锁后,处理完业务流程应该删除对应的key,如果这个过程中发生了问题,导致锁超时或者出现了异常,没有办法释放锁,就会产生死锁问题.
redis提供的另一个指令EXPIRE,来设置锁的过期时间EXPIRE KEY seconds来设置key的生存时间,如图
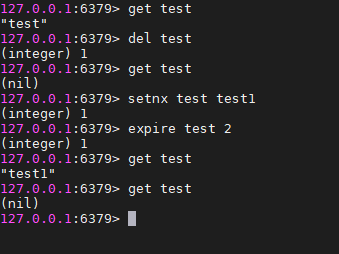
两秒以后key就被自动删除了.
但是程序里我们也不能写成如下的代码
public static void wrongGetLock1(Jedis jedis, String lockKey, String requestId, int expireTime) {
Long result = jedis.setnx(lockKey, requestId);
if (result == 1) {
jedis.expire(lockKey, expireTime);
doSomething();
}
}因为setnx和expire两个指令是两条命令并不具有原子性,如果在执行setnx后程序突然崩溃,没有设置过期时间就会发生死锁.
在redis2.6.12版本后,又提供了一个新的方案
SET key value [EX seconds] [PX millisecounds] [NX|XX] EX seconds:设置键的过期时间为second秒 PX millisecounds:设置键的过期时间为millisecounds 毫秒 NX:只在键不存在的时候,才对键进行设置操作 XX:只在键已经存在的时候,才对键进行设置操作 SET操作成功后,返回的是OK,失败返回NIL
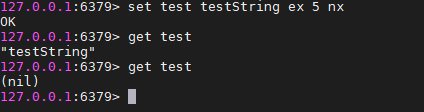
如何释放锁
释放锁的时候很容易联想到del指令,可是这个指令如果直接在代码中使用,会产生一个很严重的问题,拥有超时锁的线程会释放掉当前拥有锁的那个线程的锁
(删了不属于自己的锁)
场景:
- 线程1,2,3分别尝试加锁最后只有1成功获得锁,其他线程加锁失败继续尝试
- 线程1开始执行业务代码,线程2,3继续尝试
- 线程1的锁超时了,自动释放了锁,此时线程2获得了锁,线程3继续尝试加锁
- 线程1的任务执行完毕,使用了del指令删除锁,线程2在执行业务代码,线程3这时会获得锁(因为线程1把线程2的锁删了)
所以,我们要在set键值对的时候,保证可以区分开当前锁是否属于执行指令的这个线程,value我们可以设置为当前的requestID或线程的id
而这些步骤如果直接用代码控制则会显得较为繁琐,可以引入lua脚本
if redis.call('get', KEYS[1]) == ARGV[1]
then
return redis.call('del', KEYS[1])
else
return 0
end上述lua脚本用于比较KEYS[1]对应的VALUE和ARG[1]的值是否一直,即当前锁是否属于当前线程,如果是true则删除锁,返回del结果,否则直接返回0
执行脚本可以使用redis的eval指令
jedis.eval(String script, List<String> kyes,List<String>args);存在的问题:上面讨论的是单机redis的场景,如果是分布式下的redis哨兵集群会存在问题,如果线程1的锁加在了主库,这时候主库直接宕机,redis还没来得及将这个锁的数据同步至从节点,sentinel就将从库中的一台选举为主库了,这时候另一个线程也来进行加锁,也会成功,这时候便有两个线程同时获得了锁
这种情况可以使用Redisson redlock
javaConfig config = new Config(); config.useSentinelServers().addSentinelAddress("127.0.0.1:6369","127.0.0.1:6379", "127.0.0.1:6389") .setMasterName("masterName") .setPassword("password").setDatabase(0); RedissonClient redissonClient = Redisson.create(config); RLock redLock = redissonClient.getLock("REDLOCK_KEY"); boolean isLock; try { isLock = redLock.tryLock(500, 10000, TimeUnit.MILLISECONDS); if (isLock) { //TODO if get lock success, do something; } } catch (Exception e) { } finally { redLock.unlock(); }由于 redisson 包的实现中,通过 lua 脚本校验了解锁时的 client 身份,所以我们无需再在 finally 中去判断是否加锁成功,也无需做额外的身份校验,可以说已经达到开箱即用的程度了。
基于ZooKeeper实现分布式锁
zookeeper一般有多个节点构成(单数个),采用zab一致性协议,所以可以将zk看成一个单点结构,对其修改数据其内部会自动将所有节点进行修改才提供查询服务
zookeeper的数据是目录树的方式存储的,每个目录称为znode,znode可以存储数据,还可以在其中增加子节点
子节点有三种类型
- 序列化节点:每在该节点下增加一个节点会自动给节点的名字自增
- 临时节点:一旦创建这个节点的客户端与服务器失去联系会自动删除节点
- 普通节点
Watch机制,客户端可以监控每个节点的变化,产生变化时会给客户端产生一个事件
zookeeper分布式锁原理
- 获取和释放锁:利用临时节点的特性和watch机制,每个锁占用一个普通节点/lock,当需要获取锁时在/lock目录下创建一个临时节点,创建成功表示获取锁成功,失败则watch /lock节点,有删除操作时再去竞争锁。临时节点的好处在于当进程挂掉后自动上锁的节点会自动删除,即释放锁.
- 获取锁的顺序:上锁为创建临时有序节点,每个上锁的节点均能创建节点成功,只是序号不同,只有序号最小的才能拥有锁,如果节点序号不是最小则watch序号比自身小的前一个节点(公平锁)
获取锁的流程:
1.先有一个锁根节点,lockRootNode,可以是一个永久节点
2.客户端获取锁,先在lockRootNode下创建一个顺序的临时节点
3.调用lockRootNode节点的getChildren()方法获取所有节点,并从小到大排序,如果创建的最小的节点是当前节点,则返回true,获取锁成功,否则,watch比自己序号小的节点的释放动作(exist watch),这也可以保证每个客户端只需要watch一个节点
4.如果有节点释放操作,重复第3步
代码中可以使用Apache Curator来实现基于临时节点的分布式锁
public class CuratorDistrLockTest {
/** Zookeeper info */
private static final String ZK_ADDRESS = "192.168.1.100:2181";
private static final String ZK_LOCK_PATH = "/lockRootNode";
public static void main(String[] args) throws InterruptedException {
// 1.Connect to zk
CuratorFramework client = CuratorFrameworkFactory.newClient(
ZK_ADDRESS,
new RetryNTimes(10, 5000)
);
client.start();
System.out.println("zk client start successfully!");
Thread t1 = new Thread(() -> {
doWithLock(client);
}, "t1");
Thread t2 = new Thread(() -> {
doWithLock(client);
}, "t2");
t1.start();
t2.start();
}
private static void doWithLock(CuratorFramework client) {
InterProcessMutex lock = new InterProcessMutex(client, ZK_LOCK_PATH);
try {
if (lock.acquire(10 * 1000, TimeUnit.SECONDS)) {
System.out.println(Thread.currentThread().getName() + " hold lock");
Thread.sleep(5000L);
System.out.println(Thread.currentThread().getName() + " release lock");
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}优缺点:
优点:
- 客户端如果宕机,可以立即释放锁
- 集群模式的稳定性高
- 可以通过watch机制实现阻塞锁
缺点:
- 一旦出现网络抖动,zk就会认为客户端挂掉并断掉连接,其他客户端就会获取锁
- 性能不高,每次获取锁和释放锁都基于创建删除临时节点,zk创建和删除节点只能通过leader服务器进行,然后再同步至所有follower上