关于消息中间件MQ
本文以RabbitMQ为例
1.为什么要使用MQ
这个问题也可以理解为MQ的作用,MQ的作用:
- 异步:系统A中产生的一个数据,另外的系统BCD都需要对数据进行操作,不引入MQ时可以用A依次调用BCD的接口进行数据处理,这也就会耗费大量的时间,对于前台是无法接受的.如果引入MQ,可以将A系统的数据写入MQ,其他系统分别去消费数据,可以大大节省时间,优化体验
- 解耦:如上面所说的,不使用MQ时,需要在A系统的代码里分别调用BCD的接口,如果BCD的服务宕机就会对A系统产生影响,又或者BCD系统如果后期不需要这个数据了,那就要删除A系统中对应的代码,如果要增加E服务处理A的数据,那又要增加相应的E系统的代码,耦合严重.如果引入MQ,系统中不会存在太大影响,就算其他系统宕机,也不会对A产生影响
- 削峰:在高并发的情况下,如秒杀抢购活动,会在短时间内有大量请求涌入,如果流量太大,超过了系统的处理能力,可能就会导致我们的系统,数据库崩溃,可以将用户请求写入MQ,按照系统最大承载能力去处理请求,超过一定的阈值就将请求丢弃或给出错误提示
2.消息队列的优缺点
优点:
- 对结构复杂的操作进行解耦,降低了系统的维护成本
- 对一个可以异步进行的操作进行异步化,可以减少响应时间
- 对高并发请求进行削峰,保证系统稳定性
缺点:
系统复杂度提高。需要考虑MQ的各种情况,如消息丢失,重复消费,顺序消费等
一致性问题。如A系统返回了成功的结果,BC系统成功了但D系统失败了
系统可用性问题。如果MQ宕机,可能会导致系统的崩溃
3.如何保证消息队列高可用
RabbitMQ有三种模式:单机、普通集群、镜像集群
**普通集群:**就是在多台服务器上启动多个rabbitmq实例,但是创建的队列只会放在一个rabbitmq实例中,其他的实例会同步这个队列的元数据。消费的时候如果连接了另一个实例,也会从拥有队列的那个实例获取消息然后返回。
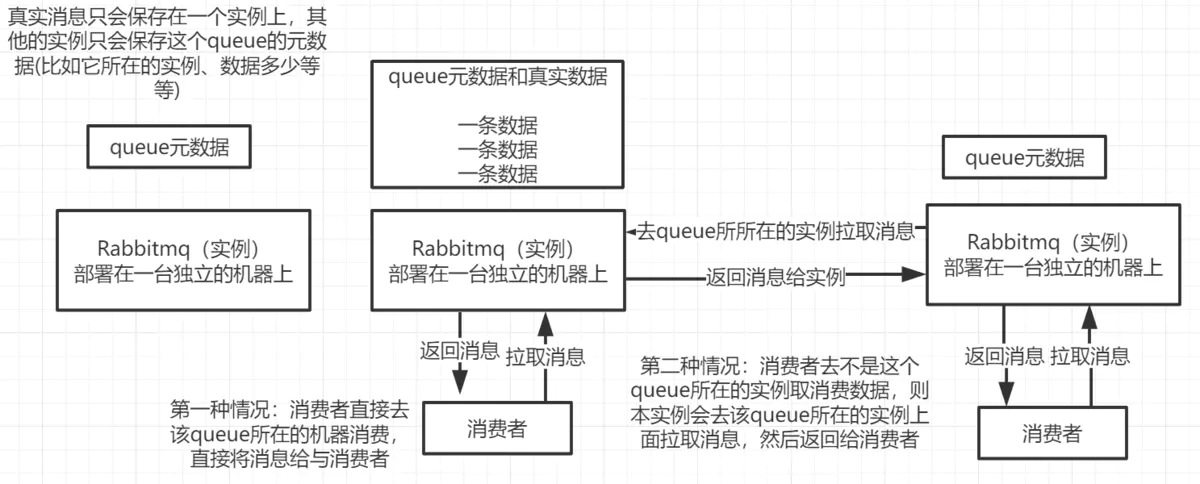
这种方案并不能做到高可用
**镜像集群:**真正的高可用模式,创建的queue无论元数据还是消息数据都存放在多个实例中,每次写消息到queue时,都会自动把消息同步到多个queue中。
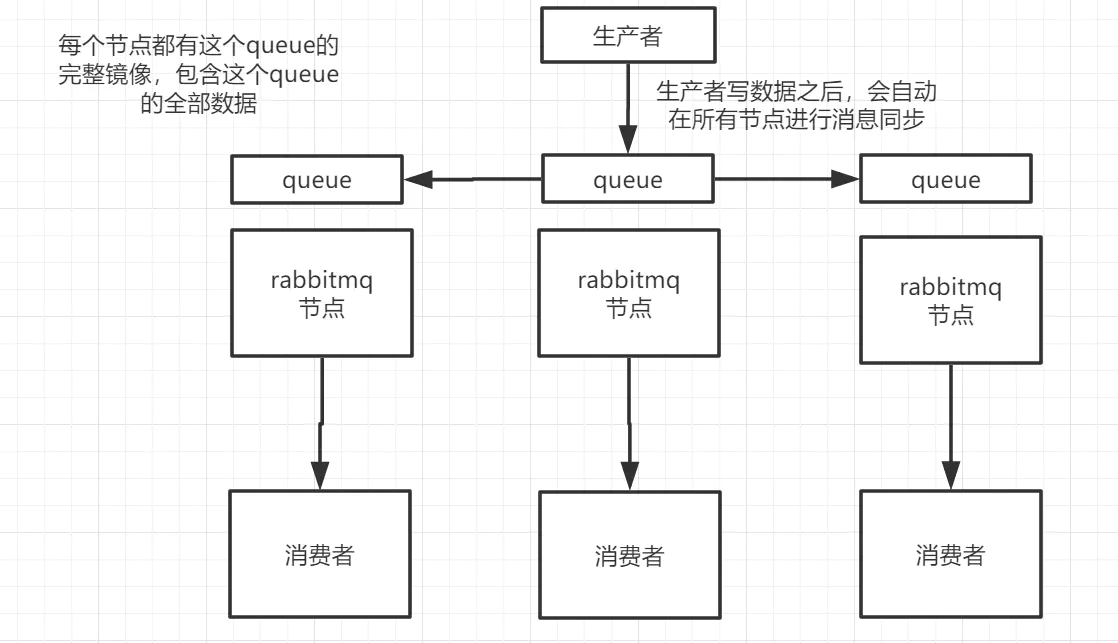
优点:实现了高可用,任何一台机器宕机,其他机器能继续使用
缺点:1、性能消耗较大,所有机器都要进行消息同步 2、没有扩展性,如果有一个queue负载很重,就算增加机器,新增的机器也包含这个queue的全部数据,
4.如何保证消息不重复消费
保证消费的幂等性,让每条消息带一个全局唯一的bizId,具体过程:
1、消费者获取消息后先根据redis/db是否有该消息
2、如果不存在,则正常消费,消费完毕后写入redis/db
3、如果已经存在,证明已经消费过,直接丢弃
5.如何保证消息不丢失
原则:数据不能多也不能少,不能多是指不重复消费,不能少是指不能丢数据
丢失数据场景:
- 生产者丢失数据:生产者发送数据到mq时可能因为网络波动丢失数据
- rabbitmq丢失数据:如果没有开启rabbitmq持久化,一旦mq重启,数据就丢了
- 消费者丢失数据:消费者刚消费到还没开始处理,消费者就挂掉了,重启后mq就认为已经消费过了,丢掉了数据
解决方案:
针对生产者丢失数据:
- rabbitmq事务,生产者发送消息前开启事务,如果消息没有发送成功生产者会收到异常报错,这时可以回滚并重试发送
channel.txSelect();
try{
//发送消息
}catch(Exception e){
channel.rollback();
//重新发送
}**缺点:**开启事务会变成阻塞操作,造成生产者的性能和吞吐量的下降
- 把channel设置成confirm模式,每次写的消息都会分配一个唯一的id,如果mq接到消息就会回调生产者的接口,通知消息已经收到,如果mq接受报错,也会回调通知,这样可以重试发送数据,伪代码如下
//开启confirm模式
channel.confirm();
//发送消息
在生产者服务提供一个回调接口的实现
public void ack(String messageId){
//已经收到消息
}
public void nack(String messageId){
//重发消息
}**针对mq丢失数据:**开启mq的持久化,将交换机/队列的durable设置为true,表示交换机/队列时持久化的,在服务崩溃或重启后无需重新创建
@RabbitListener(
bindings = {
@QueueBinding(
value = @Queue(value = "dynamicQueue", autoDelete = "false", durable = "true"),
exchange = @Exchange(value = "exchange", durable = "true", type = ExchangeTypes.DIRECT),
key = "routingKey"
)
}
)
public void dynamicQueue(Message message, Channel channel) {
System.out.println("接收消息:" + new String(message.getBody()));
}如果消息想从rabbitmq崩溃中回复,消息必须实现:
- 消息发送前,把投递模式设置为2(持久)来标记为持久消息
- 将消息发送到持久交换机
- 将消息发送到持久队列
针对消费者丢失数据:关闭消费者的autoAck机制,然后每次处理完一条消息,主动发送ack给rabbitmq,如果此时还没发送ack就宕机,mq没有收到ack消息,就会重新将消息重新分配给其他
强制消费者手动确认:
spring.rabbitmq.listener.simple.acknowledge-mode: manual消费者手动ack:
channel.basicAck(message.getMessageProperties().getDeliveryTag(), false);6.如何保证消息的顺序消费
一个queue一个consumer
7.消息积压
1.先修复consumer的问题,确保恢复消费速度,然后停掉所有consumer
2.临时建立数十倍的queue
3.写一个临时分发的consumer程序,部署上去消费积压的消息,消费不做处理,直接轮询写入上一步建好的queue中
4.重新部署consumer(机器加倍),每一批consumer消费一个临时queue