增量式爬虫实践案例 下载指定b站up主的所有作品
背景
增量式爬取指定的up主的所有投稿作品,即实现一个增量式爬虫。
这次示范的up主是个妹子😏kototo使用了scrapy框架,主要是为了练手,不使用框架反而会更简单一些。
python模块:scrapy、selenium、requests、pymysql
其他环境:ffmpeg、mysql
创建一个项目并创建爬虫
bash
scrapy startproject kototo
cd kototo
scrapy genspider kototo bilibili.com爬虫类
python
import scrapy
from selenium import webdriver
import re
import json
import requests
import os
from kototo.items import KototoItem
import pymysql
class KototoSpider(scrapy.Spider):
name = 'kototo'
start_urls = []
def __init__(self):
"""
构造器,主要初始化了selenium对象并实现无头浏览器,以及
初始化需要爬取的url地址,因为b站的翻页是js实现的,所以要手动处理一下
"""
super().__init__()
# 构造无头浏览器
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
self.bro = webdriver.Chrome(chrome_options=chrome_options)
# 指定的up主的投稿页面,可以提到外面使用input输入
space_url = 'https://space.bilibili.com/17485141/video'
# 初始化需要爬取的列表页
self.init_start_urls(self.start_urls, space_url)
# 创建桌面文件夹
self.desktop_path = os.path.join(os.path.expanduser('~'), 'Desktop\\' + self.name + '\\')
if not os.path.exists(self.desktop_path):
os.mkdir(self.desktop_path)
def parse(self, response):
"""
解析方法,解析列表页的视频li,拿到标题和详情页,然后主动请求详情页
:param response:
:return:
"""
li_list = response.xpath('//*[@id="submit-video-list"]/ul[2]/li')
for li in li_list:
print(li.xpath('./a[2]/@title').extract_first())
print(detail_url := 'https://' + li.xpath('./a[2]/@href').extract_first()[2:])
yield scrapy.Request(url=detail_url, callback=self.parse_detail)
def parse_detail(self, response):
"""
增量爬取: 解析详情页的音视频地址并交给管道处理
使用mysql实现
:param response:
:return:
"""
title = response.xpath('//*[@id="viewbox_report"]/h1/@title').extract_first()
# 替换掉视频名称中无法用在文件名中或会导致cmd命令出错的字符
title = title.replace('-', '').replace(' ', '').replace('/', '').replace('|', '')
play_info_list = self.get_play_info(response)
# 这里使用mysql的唯一索引实现增量爬取,如果是服务器上跑也可以用redis
if self.insert_info(title, play_info_list[1]):
video_temp_path = (self.desktop_path + title + '_temp.mp4').replace('-', '')
video_path = self.desktop_path + title + '.mp4'
audio_path = self.desktop_path + title + '.mp3'
item = KototoItem()
item['video_url'] = play_info_list[0]
item['audio_url'] = play_info_list[1]
item['video_path'] = video_path
item['audio_path'] = audio_path
item['video_temp_path'] = video_temp_path
yield item
else:
print(title + ': 已经下载过了!')
def insert_info(self, vtitle, vurl):
"""
mysql持久化存储爬取过的视频内容信息
:param vtitle: 标题
:param vurl: 视频链接
:return:
"""
with Mysql() as conn:
cursor = conn.cursor(pymysql.cursors.DictCursor)
try:
sql = 'insert into tb_kototo(title,url) values("%s","%s")' % (vtitle, vurl)
res = cursor.execute(sql)
conn.commit()
if res == 1:
return True
else:
return False
except:
return False
def get_play_info(self, resp):
"""
解析详情页的源代码,提取其中的视频和文件真实地址
:param resp:
:return:
"""
json_data = json.loads(re.findall('<script>window\.__playinfo__=(.*?)</script>', resp.text)[0])
# 拿到视频和音频的真实链接地址
video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]
audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]
return video_url, audio_url
def init_start_urls(self, url_list, person_page):
"""
初始化需要爬取的列表页,由于b站使用js翻页,无法在源码中找到翻页地址,
需要自己手动实现解析翻页url的操作
:param url_list:
:param person_page:
:return:
"""
mid = re.findall('https://space.bilibili.com/(.*?)/video\w*', person_page)[0]
url = 'https://api.bilibili.com/x/space/arc/search?mid=' + mid + '&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'Referer': 'https://www.bilibili.com'
}
json_data = requests.get(url=url, headers=headers).json()
total_count = json_data['data']['page']['count']
page_size = json_data['data']['page']['ps']
if total_count <= page_size:
page_count = 1
elif total_count % page_size == 0:
page_count = total_count / page_size
else:
page_count = total_count // page_size + 1
url_template = 'https://space.bilibili.com/' + mid + '/video?tid=0&page=' + '%d' + '&keyword=&order=pubdate'
for i in range(page_count):
page_no = i + 1
url_list.append(url_template % page_no)
def closed(self, spider):
"""
爬虫结束关闭selenium窗口
:param spider:
:return:
"""
self.bro.quit()
class Mysql(object):
def __enter__(self):
self.connection = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='root', database='python')
return self.connection
def __exit__(self, exc_type, exc_val, exc_tb):
self.connection.close()下载中间件
python
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class KototoSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn’t have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class KototoDownloaderMiddleware:
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
"""
篡改列表页的响应数据:
视频列表是通过ajax请求动态加载的,因此要通过selenium去加载这部分数据
并篡改响应内容
:param request:
:param response:
:param spider:
:return:
"""
urls = spider.start_urls
bro = spider.bro
from scrapy.http import HtmlResponse
from time import sleep
if request.url in urls:
"""
如果是列表页就进行响应篡改操作
"""
bro.get(request.url)
sleep(3)
page_data = bro.page_source
new_response = HtmlResponse(url=request.url, body=page_data, encoding='utf-8', request=request)
# 返回篡改过的响应对象
return new_response
return response
def process_exception(self, request, exception, spider):
passItem
python
import scrapy
class KototoItem(scrapy.Item):
video_path = scrapy.Field()
video_url = scrapy.Field()
audio_path = scrapy.Field()
audio_url = scrapy.Field()
video_temp_path = scrapy.Field()Pipeline
python
import requests
import os
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',
'Referer': 'https://www.bilibili.com'
}
class KototoPipeline(object):
def process_item(self, item, spider):
video = item['video_url']
audio = item['audio_url']
video_temp_path = item['video_temp_path']
audio_path = item['audio_path']
video_data = requests.get(url=video, headers=headers).content
audio_data = requests.get(url=audio, headers=headers).content
with open(video_temp_path, 'wb') as f:
f.write(video_data)
with open(audio_path, 'wb') as f:
f.write(audio_data)
return item
class MergePipeline(object):
"""
删除临时文件
"""
def process_item(self, item, spider):
video_temp_path = item['video_temp_path']
audio_path = item['audio_path']
video_path = item['video_path']
cmd = 'ffmpeg -y -i ' + video_temp_path + ' -i ' \
+ audio_path + ' -c:v copy -c:a aac -strict experimental ' + video_path
print(cmd)
# subprocess.Popen(cmd, shell=True)
os.system(cmd)
os.remove(video_temp_path)
os.remove(audio_path)
print(video_path, '下载完成')
return itemsettings
python
BOT_NAME = 'kototo'
SPIDER_MODULES = ['kototo.spiders']
NEWSPIDER_MODULE = 'kototo.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
ROBOTSTXT_OBEY = False
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Referer': 'https://space.bilibili.com/17485141/video',
'Origin': 'https://space.bilibili.com'
}
FILES_STORE = './files'
DOWNLOADER_MIDDLEWARES = {
'kototo.middlewares.KototoDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
# 下载
'kototo.pipelines.KototoPipeline': 1,
# 合并
'kototo.pipelines.MergePipeline': 2,
}启动
命令启动:
scrapy crawl kototo配置pycharm启动(推荐)
下载结果
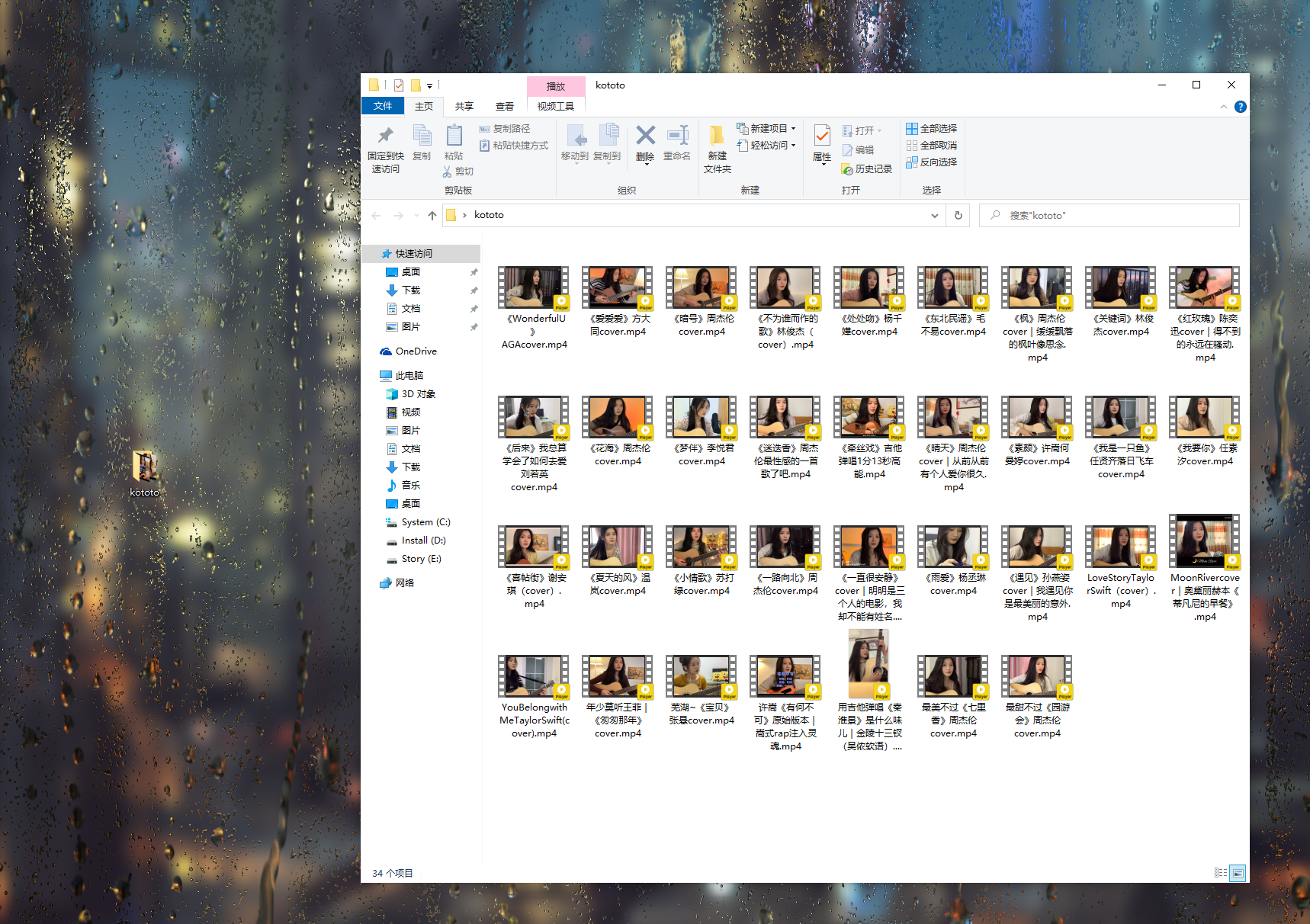
mysql
再次尝试下载时
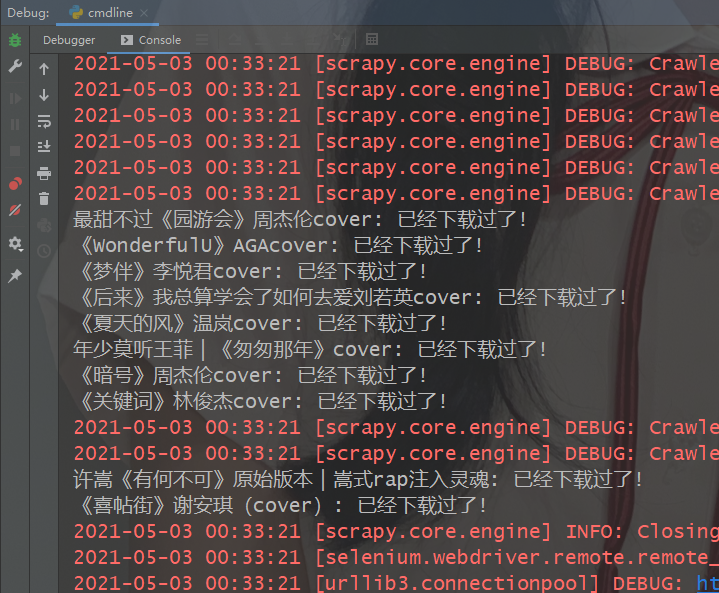
已经爬取过的资源会提示已经下载过,只会处理更新的内容。