canal部署
canal官方仓库:https://github.com/alibaba/canal/
wiki:https://github.com/alibaba/canal/wiki
canal的用途是基于mysql的binlog日志解析,提供增量数据的订阅和消费。简单的场景:通过canal监控mysql数据变更从而及时更新redis中对应的缓存或更新es中的文档内容
本文主要介绍canal在服务器端的部署,包括canal-admin,canal-tsdb配置以及instance配置。mysql版本为5.7,系统为macOS14.2.1。
首先需要下载canal的发行版,下载地址:https://github.com/alibaba/canal/releases,可自行选择版本,这里选择1.1.4。
mysql
自建MySQL,需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复canal admin
- 解压
mkdir -p ~/Downloads/canal/admin && tar -zxvf canal.admin-1.1.4.tar.gz -C ~/Downloads/canal/admin执行conf文件夹中的canal_manager.sql建表
shellmysql -uroot -p < ~/Downloads/canal/admin/conf/canal_manager.sql
创建
canal用户并授权canal链接 MySQL 账号具有作为 MySQL slave 的权限sqlCREATE USER canal IDENTIFIED BY 'canal'; GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%'; -- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ; FLUSH PRIVILEGES;
修改conf文件夹中的application.yml
执行admin/bin目录的startup.sh
访问8089端口
使用默认账号密码 admin/123456即可登录
TIP
application.yml中的canal.adminUser和canal.adminPasswd并非WebUI的登录用户名和密码,而是和canal-server交互用的
canal-admin的核心模型主要有:
- instance,对应canal-server里的instance,一个最小的订阅mysql的队列
- server,对应canal-server,一个server里可以包含多个instance
- 集群,对应一组canal-server,组合在一起面向高可用HA的运维
简单解释:
- instance是最原始的业务订阅诉求,它会和 server/集群 这两个面向资源服务属性的进行关联,比如instance A绑定到server A上或者集群 A上,
- 有了任务和资源的绑定关系后,对应的资源服务就会接收到这个任务配置,在对应的资源上动态加载instance,并提供服务
- 动态加载的过程,对应配置文件中的autoScan配置,只不过基于canal-admin之后可就以变为远程的web操作,而不需要在机器上运维配置文件
- 将server抽象成资源之后,原本canal-server运行所需要的canal.properties/instance.properties配置文件就需要在web ui上进行统一运维,每个server只需要以最基本的启动配置 (比如知道一下canal-admin的manager地址,以及访问配置的账号、密码即可)
新建server,按照图中配置即可
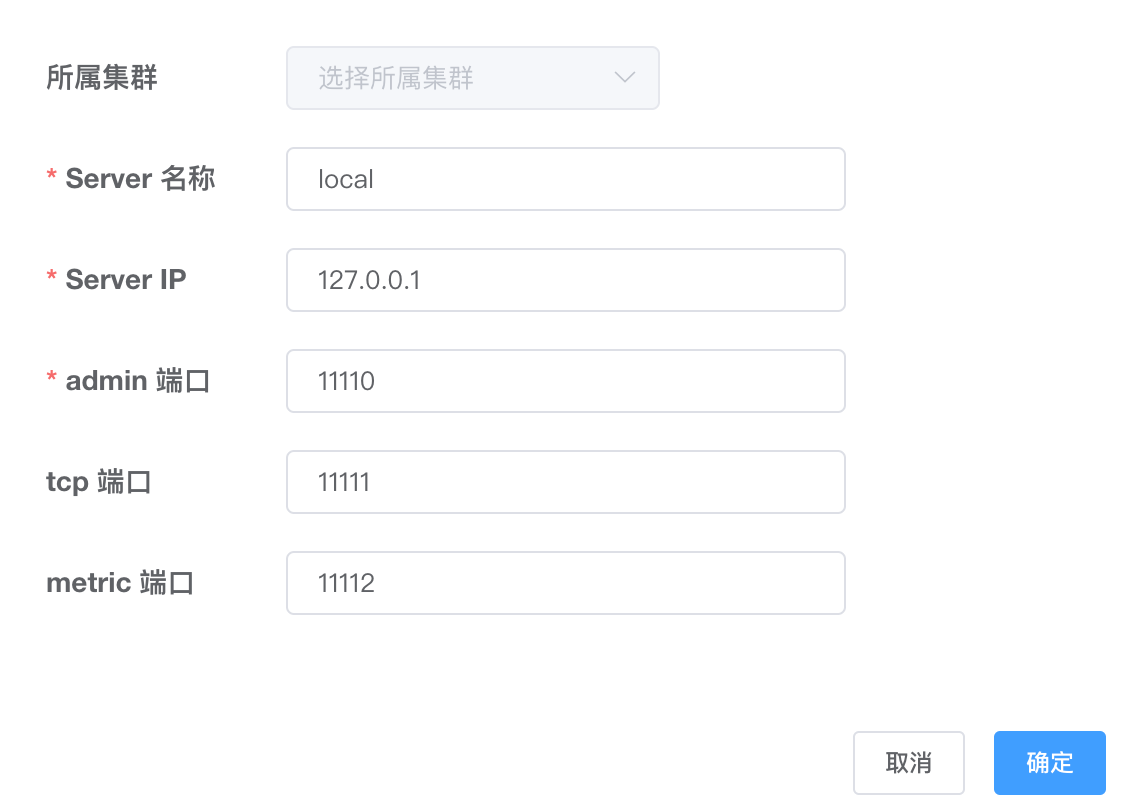
配置项:
- 所属集群,可以选择为单机 或者 集群。一般单机Server的模式主要用于一次性的任务或者测试任务
- Server名称,唯一即可,方便自己记忆
- Server Ip,机器ip
- admin端口,canal 1.1.4版本新增的能力,会在canal-server上提供远程管理操作,默认值11110
- tcp端口,canal提供netty数据订阅服务的端口
- metric端口, promethues的exporter监控数据端口 (未来会对接监控)
server端配置
- 修改为kafka模式并配置kafka相关参数
- tsdb改为mysql
#################################################
######### common argument #############
#################################################
# tcp bind ip
canal.ip =
# register ip to zookeeper
canal.register.ip =
canal.port = 11111
canal.metrics.pull.port = 11112
# canal instance user/passwd
canal.user = canal
canal.passwd = E3619321C1A937C46A0D8BD1DAC39F93B27D4458
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
canal.zkServers =
# flush data to zk
canal.zookeeper.flush.period = 1000
canal.withoutNetty = false
# tcp, kafka, RocketMQ
canal.serverMode = kafka
# flush meta cursor/parse position to file
canal.file.data.dir = ${canal.conf.dir}
canal.file.flush.period = 1000
## memory store RingBuffer size, should be Math.pow(2,n)
canal.instance.memory.buffer.size = 16384
## memory store RingBuffer used memory unit size , default 1kb
canal.instance.memory.buffer.memunit = 1024
## meory store gets mode used MEMSIZE or ITEMSIZE
canal.instance.memory.batch.mode = MEMSIZE
canal.instance.memory.rawEntry = true
## detecing config
canal.instance.detecting.enable = false
#canal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()
canal.instance.detecting.sql = select 1
canal.instance.detecting.interval.time = 3
canal.instance.detecting.retry.threshold = 3
canal.instance.detecting.heartbeatHaEnable = false
# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery
canal.instance.transaction.size = 1024
# mysql fallback connected to new master should fallback times
canal.instance.fallbackIntervalInSeconds = 60
# network config
canal.instance.network.receiveBufferSize = 16384
canal.instance.network.sendBufferSize = 16384
canal.instance.network.soTimeout = 30
# binlog filter config
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = false
canal.instance.filter.query.dml = false
canal.instance.filter.query.ddl = false
canal.instance.filter.table.error = false
canal.instance.filter.rows = false
canal.instance.filter.transaction.entry = false
# binlog format/image check
canal.instance.binlog.format = ROW,STATEMENT,MIXED
canal.instance.binlog.image = FULL,MINIMAL,NOBLOB
# binlog ddl isolation
canal.instance.get.ddl.isolation = false
# parallel parser config
canal.instance.parser.parallel = true
## concurrent thread number, default 60% available processors, suggest not to exceed Runtime.getRuntime().availableProcessors()
#canal.instance.parser.parallelThreadSize = 16
## disruptor ringbuffer size, must be power of 2
canal.instance.parser.parallelBufferSize = 256
# table meta tsdb info
canal.instance.tsdb.enable = true
#canal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}
#canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;
canal.instance.tsdb.dbUsername = canal
canal.instance.tsdb.dbPassword = canal
# dump snapshot interval, default 24 hour
canal.instance.tsdb.snapshot.interval = 24
# purge snapshot expire , default 360 hour(15 days)
canal.instance.tsdb.snapshot.expire = 360
# aliyun ak/sk , support rds/mq
canal.aliyun.accessKey =
canal.aliyun.secretKey =
#################################################
######### destinations #############
#################################################
canal.destinations =
# conf root dir
canal.conf.dir = ../conf
# auto scan instance dir add/remove and start/stop instance
canal.auto.scan = true
canal.auto.scan.interval = 5
#canal.instance.tsdb.spring.xml = classpath:spring/tsdb/h2-tsdb.xml
canal.instance.tsdb.spring.xml = classpath:spring/tsdb/mysql-tsdb.xml
canal.instance.global.mode = manager
canal.instance.global.lazy = false
canal.instance.global.manager.address = ${canal.admin.manager}
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xml
##################################################
######### MQ #############
##################################################
canal.mq.servers = 127.0.0.1:9092
canal.mq.retries = 0
canal.mq.batchSize = 16384
canal.mq.maxRequestSize = 1048576
canal.mq.lingerMs = 100
canal.mq.bufferMemory = 33554432
canal.mq.canalBatchSize = 50
canal.mq.canalGetTimeout = 100
canal.mq.flatMessage = true
canal.mq.compressionType = none
canal.mq.acks = all
#canal.mq.properties. =
canal.mq.producerGroup = canal-test
# Set this value to "cloud", if you want open message trace feature in aliyun.
canal.mq.accessChannel = local
# aliyun mq namespace
#canal.mq.namespace =
##################################################
######### Kafka Kerberos Info #############
##################################################
canal.mq.kafka.kerberos.enable = false
canal.mq.kafka.kerberos.krb5FilePath = "../conf/kerberos/krb5.conf"
canal.mq.kafka.kerberos.jaasFilePath = "../conf/kerberos/jaas.conf"TIP
canal.auto.scan如果设置为true,canal.destinations可以不填写,server会自动扫描instance然后启动
// CanalController
// 初始化monitor机制
autoScan = BooleanUtils.toBoolean(getProperty(properties, CanalConstants.CANAL_AUTO_SCAN));
if (autoScan) {
defaultAction = new InstanceAction() {
public void start(String destination) {
InstanceConfig config = instanceConfigs.get(destination);
if (config == null) {
// 重新读取一下instance config
config = parseInstanceConfig(properties, destination);
instanceConfigs.put(destination, config);
}
if (!embededCanalServer.isStart(destination)) {
// HA机制启动
ServerRunningMonitor runningMonitor = ServerRunningMonitors.getRunningMonitor(destination);
if (!config.getLazy() && !runningMonitor.isStart()) {
runningMonitor.start();
}
}
logger.info("auto notify start {} successful.", destination);
}
//...
}
}
instanceConfigMonitors = MigrateMap.makeComputingMap(new Function<InstanceMode, InstanceConfigMonitor>() {
public InstanceConfigMonitor apply(InstanceMode mode) {
int scanInterval = Integer.valueOf(getProperty(properties,
CanalConstants.CANAL_AUTO_SCAN_INTERVAL,
"5"));
if (mode.isSpring()) {
SpringInstanceConfigMonitor monitor = new SpringInstanceConfigMonitor();
monitor.setScanIntervalInSecond(scanInterval);
monitor.setDefaultAction(defaultAction);
// 设置conf目录,默认是user.dir + conf目录组成
String rootDir = getProperty(properties, CanalConstants.CANAL_CONF_DIR);
if (StringUtils.isEmpty(rootDir)) {
rootDir = "../conf";
}
if (StringUtils.equals("otter-canal", System.getProperty("appName"))) {
monitor.setRootConf(rootDir);
} else {
// eclipse debug模式
monitor.setRootConf("src/main/resources/");
}
return monitor;
} else if (mode.isManager()) {
ManagerInstanceConfigMonitor monitor = new ManagerInstanceConfigMonitor();
monitor.setScanIntervalInSecond(scanInterval);
monitor.setDefaultAction(defaultAction);
String managerAddress = getProperty(properties, CanalConstants.CANAL_ADMIN_MANAGER);
monitor.setConfigClient(getManagerClient(managerAddress));
return monitor;
} else {
throw new UnsupportedOperationException("unknow mode :" + mode + " for monitor");
}
}
});
// CanalController.start()
public void start() throws Throwable {
// ...
// 尝试启动一下非lazy状态的通道
for (Map.Entry<String, InstanceConfig> entry : instanceConfigs.entrySet()) {
final String destination = entry.getKey();
InstanceConfig config = entry.getValue();
// 创建destination的工作节点
if (!embededCanalServer.isStart(destination)) {
// HA机制启动
ServerRunningMonitor runningMonitor = ServerRunningMonitors.getRunningMonitor(destination);
if (!config.getLazy() && !runningMonitor.isStart()) {
runningMonitor.start();
}
}
if (autoScan) {
instanceConfigMonitors.get(config.getMode()).register(destination, defaultAction);
}
}
if (autoScan) {
instanceConfigMonitors.get(globalInstanceConfig.getMode()).start();
for (InstanceConfigMonitor monitor : instanceConfigMonitors.values()) {
if (!monitor.isStart()) {
monitor.start();
}
}
}
// ...
}
// 然后会调用ManagerInstanceConfigMonitor的start方法,start方法会启动一个定时任务,每隔scanInterval秒调用scan方法
public void start() {
super.start();
executor.scheduleWithFixedDelay(new Runnable() {
public void run() {
try {
scan();
if (isFirst) {
isFirst = false;
}
} catch (Throwable e) {
logger.error("scan failed", e);
}
}
}, 0, scanIntervalInSecond, TimeUnit.SECONDS);
}
// scan方法中会通过configClient调用canal-admin的接口获取instance的配置信息,
// 最后对instance进行stop/reload/start操作
private void scan() {
String instances = configClient.findInstances(null);
final List<String> is = Lists.newArrayList(StringUtils.split(instances, ','));
List<String> start = Lists.newArrayList();
List<String> stop = Lists.newArrayList();
List<String> restart = Lists.newArrayList();
for (String instance : is) {
if (!configs.containsKey(instance)) {
PlainCanal newPlainCanal = configClient.findInstance(instance, null);
if (newPlainCanal != null) {
configs.put(instance, newPlainCanal);
start.add(instance);
}
} else {
PlainCanal plainCanal = configs.get(instance);
PlainCanal newPlainCanal = configClient.findInstance(instance, plainCanal.getMd5());
if (newPlainCanal != null) {
// 配置有变化
restart.add(instance);
configs.put(instance, newPlainCanal);
}
}
}
configs.forEach((instance, plainCanal) -> {
if (!is.contains(instance)) {
stop.add(instance);
}
});
stop.forEach(instance -> {
notifyStop(instance);
});
restart.forEach(instance -> {
notifyReload(instance);
});
start.forEach(instance -> {
notifyStart(instance);
});
}canal deployer
- 解压
mkdir -p ~/Downloads/canal/deployer && tar -zxvf canal.deployer-1.1.4.tar.gz -C ~/Downloads/canal/deployer用conf目录下的canal_local.properties替换canal.properties
修改配置
properties# canal.ip canal.ip = 127.0.0.1 # register ip canal.register.ip = 127.0.0.1TIP
注意ip前后不能有空格,不然会无法启动netty server从而无法启动canal server,应该是后台没做trim
如果不填写
canal.ip和canal.register.ip两个配置项,代码中将通过AddressUtils.getHostIp()获取本机的ip地址,如果本地有docker/orbstack等创建的虚拟网络设备会导致启动canal-server后识别到多个server且是不同的ip(docker0网桥或orbstack容器等的ip),比较膈应人。(#issue47)
源码:
java// CanalController.java if (StringUtils.isEmpty(ip) && StringUtils.isEmpty(registerIp)) { ip = registerIp = AddressUtils.getHostIp(); } if (StringUtils.isEmpty(ip)) { ip = AddressUtils.getHostIp(); } if (StringUtils.isEmpty(registerIp)) { registerIp = ip; // 兼容以前配置 }执行bin目录下的startup.sh
直接在canal admin的webUI界面中配置instance,等待启动即可,如有问题查看
deploy/logs/story/story.log具体配置项参见wiki
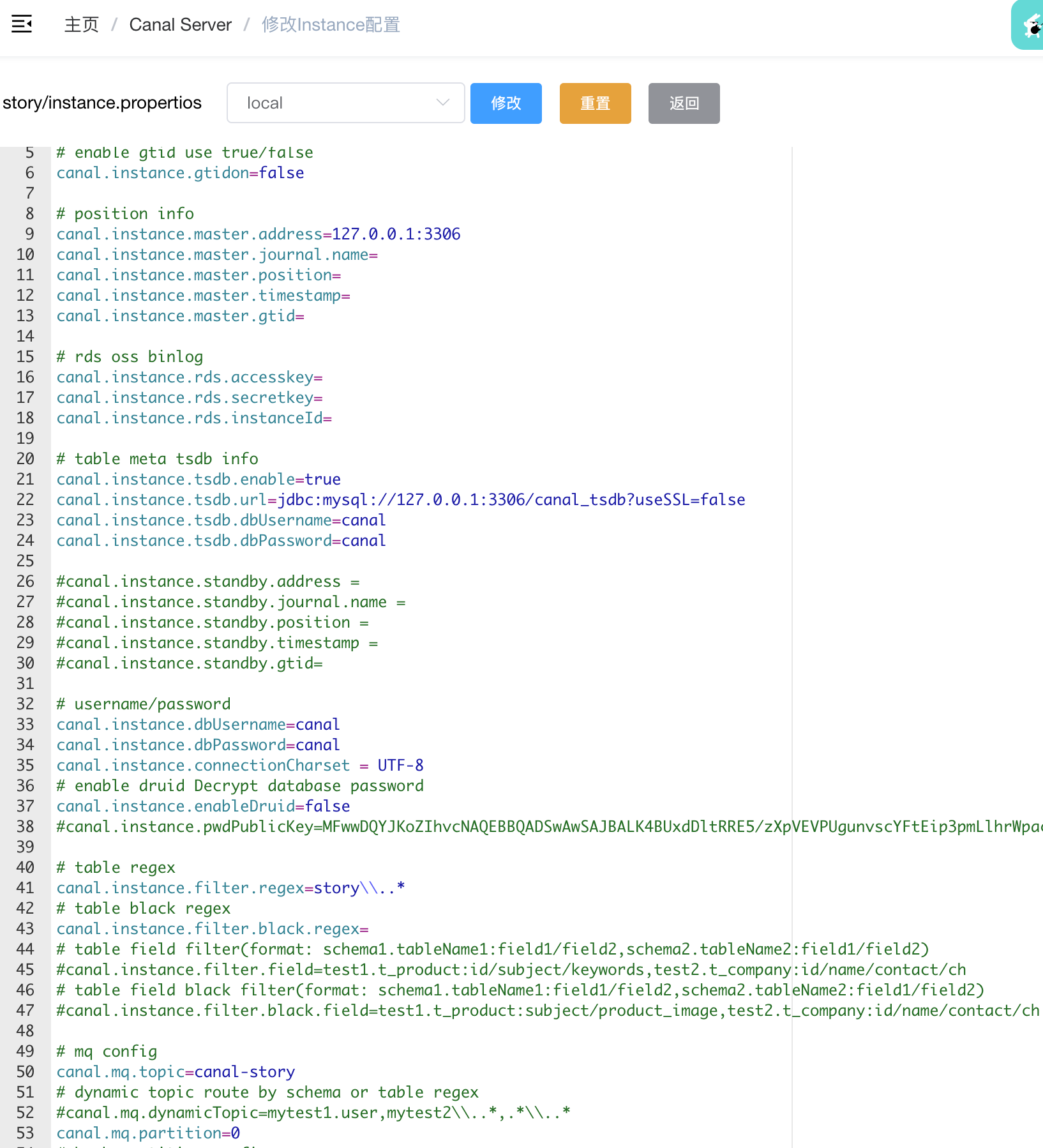
TIP
如果在server的配置文件中填了相同的配置项,那么instance中的配置会被server中的覆盖,例如canal.instance.tsdb.url配置(#issue4669)
验证
此时我们的实例story已经开始监听story数据库下面的操作,如果有变更,就会推送至kafka的canal-story这个topic中
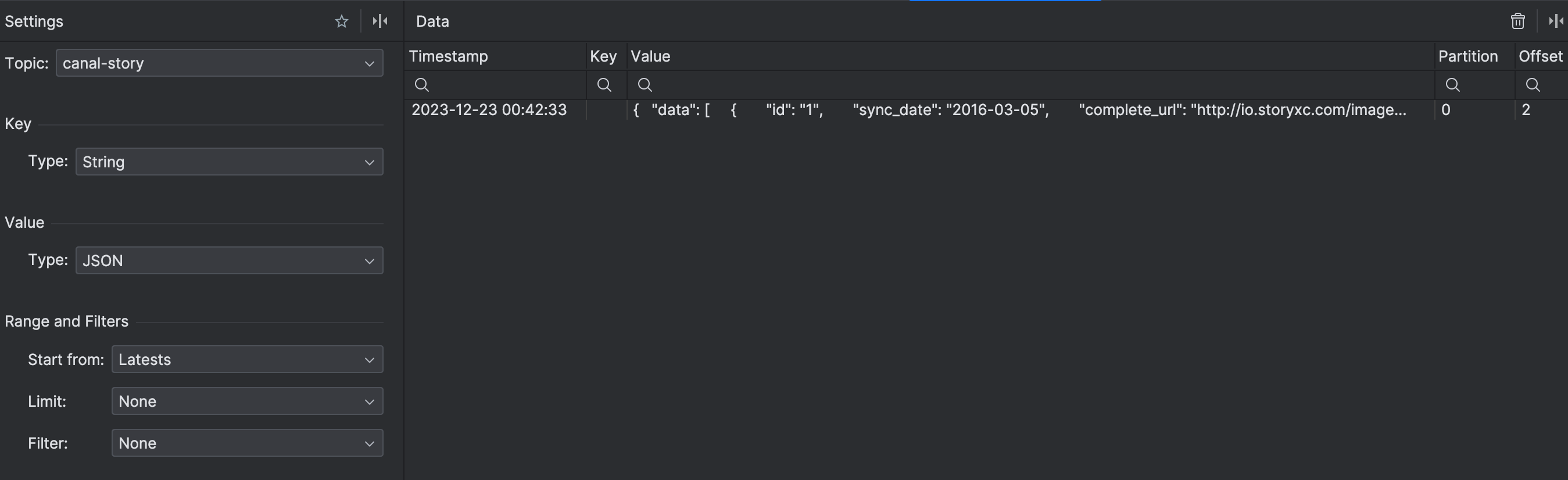
之后就需要通过业务端根据情况监听队列中的数据变化,做相应的操作。